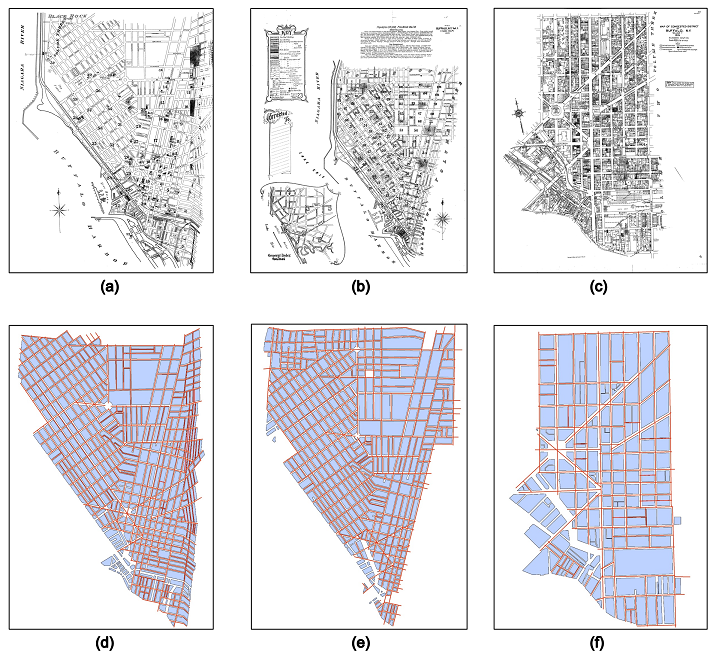
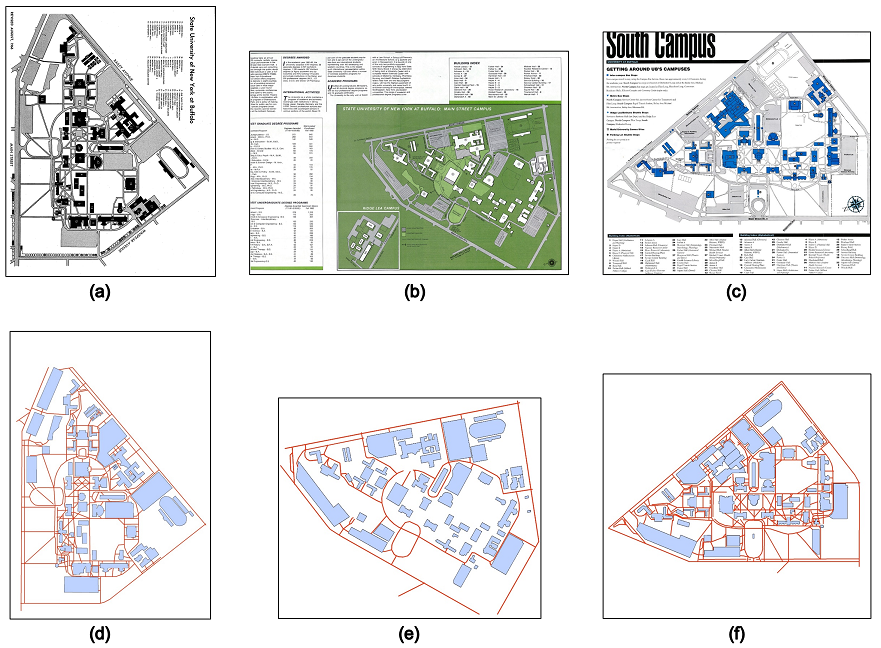
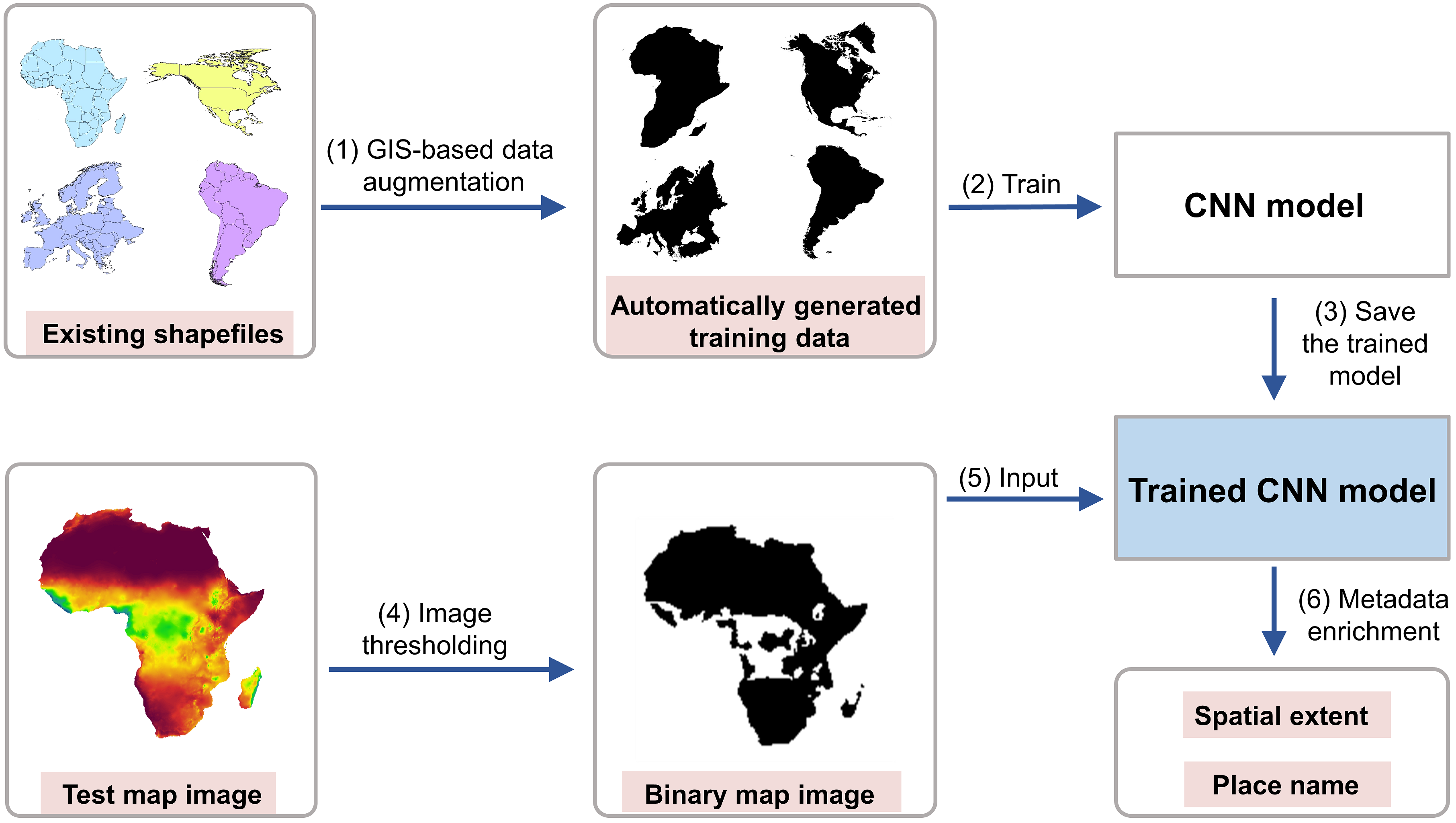
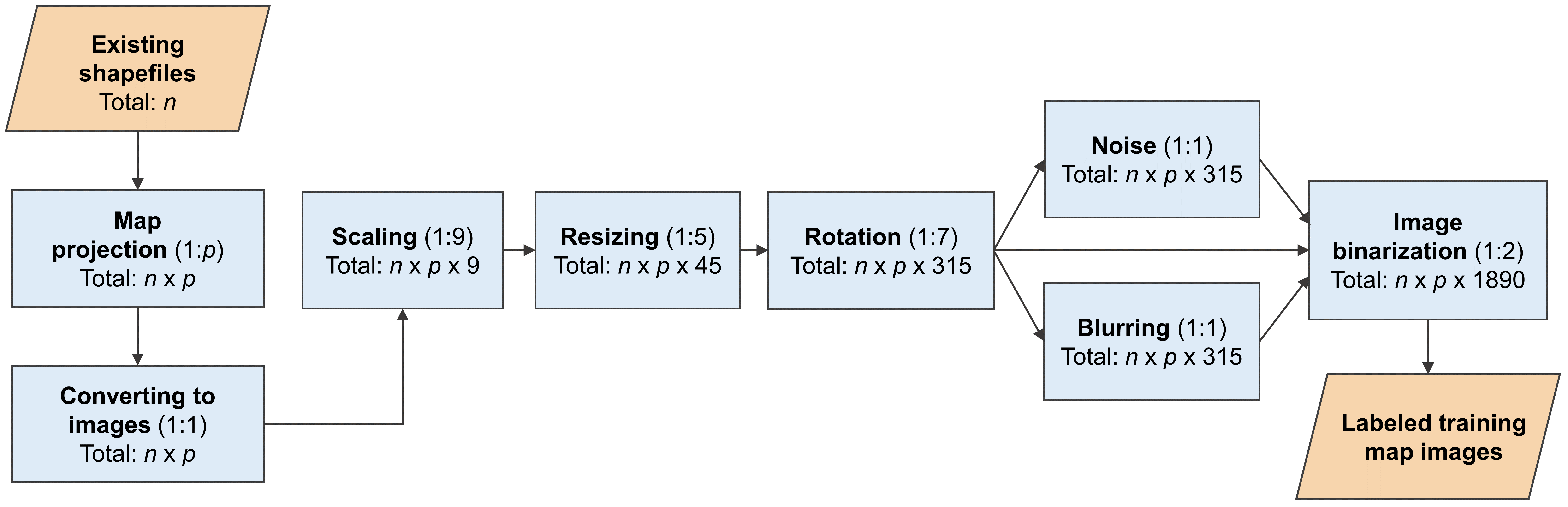
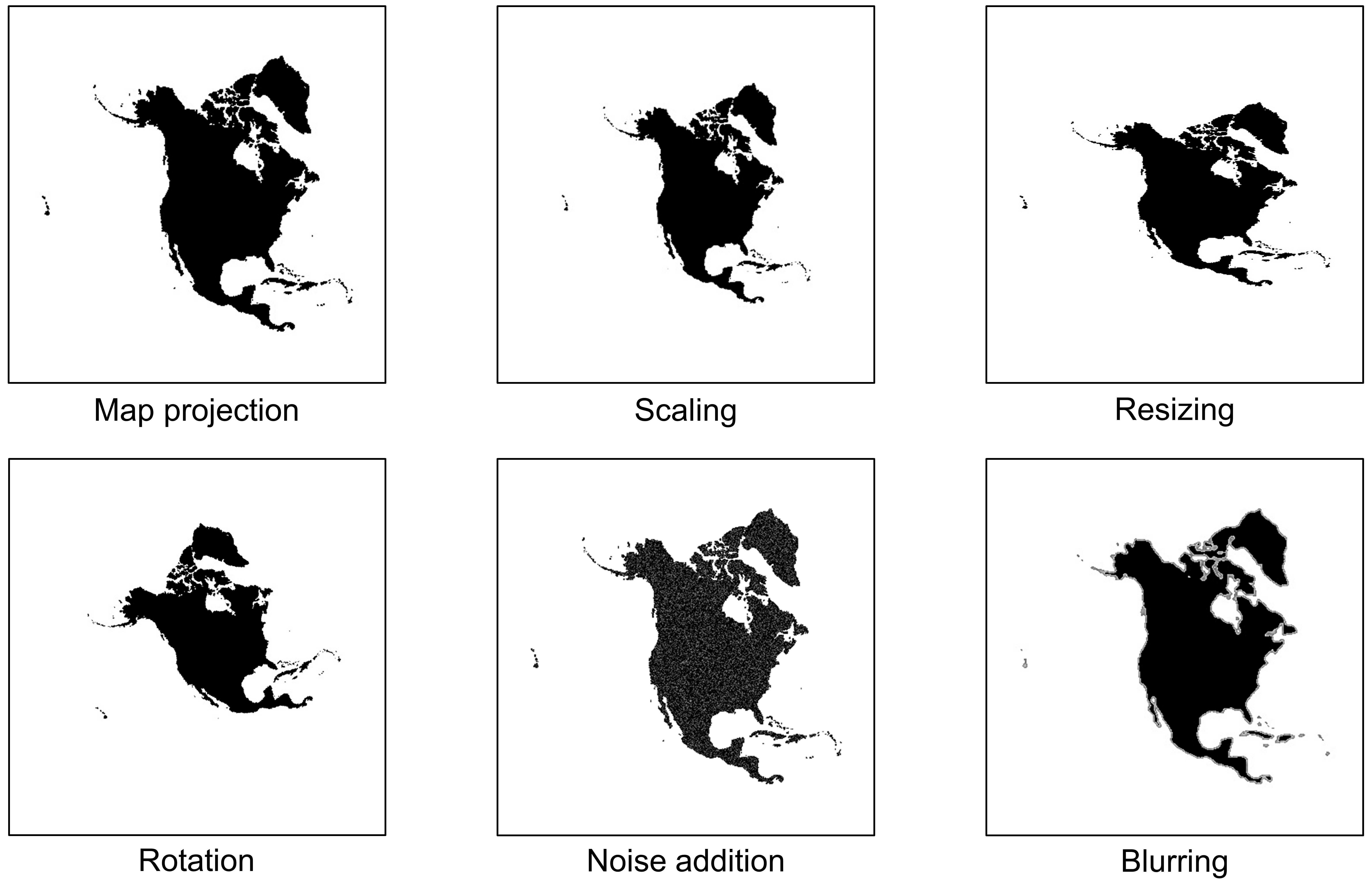
Maps in the form of digital images are widely available in geoportals, Web pages, and other data sources. The metadata of map images, such as spatial extents and place names, are critical for their indexing and searching. However, many map images have either mismatched metadata or no metadata at all. Recent developments in deep learning offer new possibilities for enriching the metadata of map images via image-based information extraction. One major challenge of using deep learning models is that they often require large amounts of training data that have to be manually labeled. To address this challenge, this paper presents a deep learning approach with GIS-based data augmentation that can automatically generate labeled training map images from shapefiles using GIS operations. We utilize such an approach to enrich the metadata of map images by adding spatial extents and place names extracted from map images. We evaluate this GIS-based data augmentation approach by using it to train multiple deep learning models and testing them on two different datasets: a Web Map Service image dataset at the continental scale and an online map image dataset at the state scale. We then discuss the advantages and limitations of the proposed approach.
More details are available in our paper at:
Yingjie Hu, Zhipeng Gui, Jimin Wang, and Muxian Li (2021): Enriching the metadata of map images: a deep learning approach with GIS-based data augmentation. International Journal of Geographical Information Science, in press. [PDF]